xCloth: Extracting Template-free Textured 3D Clothes from a Monocular Image"
(ACM Multimedia-2022)

Abstract
Existing approaches for 3D garment reconstruction either assume a predefined template for the garment geometry (restricting them to fixed clothing styles) or yield vertex colored meshes (lacking high-frequency textural details). Our novel framework co-learns geometric and semantic information of garment surface from the input monocular image for template-free textured 3D garment digitization. More specifically, we propose to extend PeeledHuman representation to predict the pixel-aligned, layered depth and semantic maps to extract 3D garments. The layered representation is further exploited to UV parametrize the arbitrary surface of the extracted garment without any human intervention to form a UV atlas. The texture is then imparted on the UV atlas in a hybrid fashion by first projecting pixels from the input image to UV space for the visible region, followed by inpainting the occluded regions. Thus, we are able to digitize arbitrarily loose clothing styles while retaining high-frequency textural details from a monocular image. We achieve high-fidelity 3D garment reconstruction results on three publicly available datasets and generalization on internet images.
Method
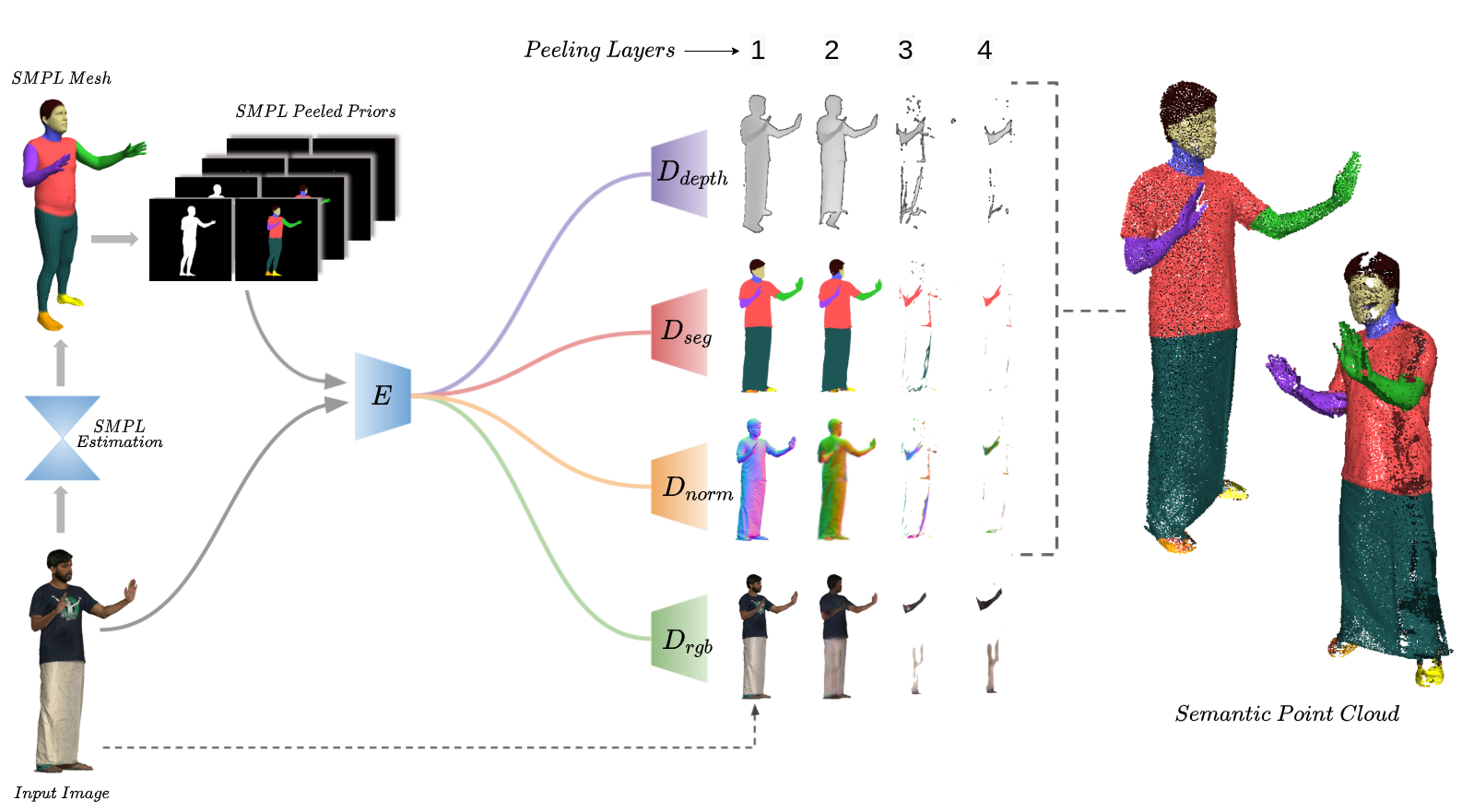
Comparison

Results on Internet Images

360° Visualizations


Applications


BibTex
@article{Srivastava2022xClothET,
title={xCloth: Extracting Template-free Textured 3D Clothes from a Monocular Image},
author={Astitva Srivastava and Chandradeep Pokhariya and Sai Sagar Jinka and Avinash Sharma},
journal={Proceedings of the 30th ACM International Conference on Multimedia},
year={2022}
}